Kontraktsrettslig skråblikk på bruk av innsamlet data
Av Andreas A. Johansen, Partner i Advokatfirmaet Schjødt, hvor han spesialiserer seg i kontraktsrett og tvisteløsning, herunder knyttet til IT-kontrakter og Anna Eide, Senior Associate i Advokatfirmaet Schjødt. Hun arbeider særlig med IP, IT og teknologi.


Illustrasjon: Colourbox.com
I stadig økende grad preges næringslivet og nyhetsbildet av saker om deling eller annen bruk av innsamlet data. Data har som kjent blitt omtalt som den nye oljen. I uraffinert form har både oljen og data liten verdi. Verdiskapningen ligger nettopp i resultatet en kan oppnå ved å sammenstille, analysere og kombinere data på en hensiktsmessig og gunstig måte. Det er forsøket på denne verdiskapningen som har preget nyhetsbildet i den siste tiden, gjennom et KI-kappløp mellom de store aktørene i næringslivet. Kappløpet er også oppmuntret av myndighetene i Norge, som blant annet har satt av en milliard kroner til forsking på kunstig intelligens.(1)https://www.regjeringen.no/no/aktuelt/regjeringen-med-milliardsatsing-pa-kunstig-intelligens/id2993214/ Samtidig vil selskaper som ønsker å ta del i kappløpet eller bruke KI-løsninger stå overfor en rekke juridiske problemstillinger.
Generelt synes det å være en bred oppfatning om at utviklingen av kunstig intelligens kan gi et positivt tilskudd til både samfunnet som sådan og næringslivet. Bruken av innsamlet data reiser imidlertid en rekke komplekse juridiske problemstillinger. Disse problemstillingene har ikke bare en personvernrettslig side, men også en kontraktsrettslig side. Hvordan skal bedrifter som analyserer og samler inn store mengder data for utvikling og innovasjon sikre at bruken av data skjer på en etisk og ansvarlig måte? Og hvordan skal bedrifter sikre seg mot at egen data brukes på en måte som er egnet til å skade egen virksomhet? Hvordan bør avtaler som har en berøringsside mot KI utformes for å beskytte individers og næringslivets interesser på en best mulig måte? I denne artikkelen vil vi se på enkelte av de kontraktsrettslige sidene ved bruk av data i KI-løsninger.
Overordnet kan det skilles mellom kontrakter som inngås mellom bedrifter og forbrukere, såkalte «B2C»-forhold (business-to-consumer), og kontrakter som inngås mellom bedrifter, såkalte «B2B»-forhold (business-to-business). I B2C-segmentet står personvern svært sentralt. De klart fleste sett med data vil her inkludere personopplysninger. I B2B-segmentet vil det i større grad være tale om data som ikke utgjør personopplysninger, eller hvor det personvernrettslige for eksempel kan reguleres gjennom en databehandleravtale. Det blir da også større rom for en «friere» avtaleregulering av bruk av data. Kontraktsretten har derfor i praksis størst plass i B2B-forhold, men vi vil likevel nedenfor starte med noen betraktninger også om B2C.
Den kontraktsrettslige siden i et B2C-forhold er velkjent for de fleste. Det er hovedregelen snarere enn unntaket at forbrukeren aksepterer tjenestens vilkår uten å ha lest vilkårene. Disse vilkårene vil svært ofte gi selskapet kontraktsrettslig grunnlag til et visst omfang av deling eller annen bruk av data. Selv om det foreligger et kontraktsrettslig grunnlag for å samle inn og bruke dataen, vil dataen som innsamles fra en forbruker nesten uten unntak inneholde personopplysninger. Når personopplysninger samles inn eller behandles, kreves det i tillegg et behandlingsgrunnlag etter personvernforordningen artikkel 6 og i enkelte tilfeller også artikkel 9.
Personvernforordningen artikkel 6 oppstiller flere behandlingsgrunnlag, deriblant avtale. Selv om det er inngått en avtale mellom selskapet og individet, er imidlertid ikke dette ensbetydende med at selve avtalen kan utgjøre et rettslig grunnlag for behandlingen av personopplysninger. For at avtalegrunnlaget skal kunne brukes, må behandlingen være nødvendig for å oppfylle avtalen med individet. Dette er tolket dithen at den behandlingsansvarlige (i vårt tilfelle selskapet) må kunne demonstrere at kontraktens hovedinnhold ikke kan oppnås uten den aktuelle behandlingen. Her er det ikke tilstrekkelig at behandlingen er gjort til en del av avtalen (f.eks. «bundlet» inn i vilkårene), eller at behandlingen er svært nyttig for selskapet. Det sentrale er om behandlingen er «objektivt uunnværlig for å gjennomføre et formål som er integrert del av den kontraktsmessige ytelsen til individet».(2)Sak C-252/21 Meta Behandling av personopplysninger for utvikling og trening av KI-verktøy vil derfor svært sjeldent eller aldri være strengt nødvendig for å oppfylle en avtale med individet i et B2C-forhold. Selve avtalen kan derfor ikke utgjøre det rettslige grunnlaget for behandlingen av personopplysninger i slike tilfeller. I personvernmiljøet er det i dag også uenighet om hvilket alternativt grunnlag som faktisk kan brukes. Vi vil imidlertid ikke gå nærmere inn på denne diskusjonen.
Bruk av data kan også være omstridt i «B2B»-forhold (business-to-business). Rettigheter til bruk av data kan reise flere problemstillinger knyttet til utforming av ansvarsreguleringer, håndtering av informasjonssikkerhet, regulering av eierskap til data, osv.
Følgende eksempel kan illustrere problemstillingen:
Et teknologiselskap selger en teknologi som samler inn data om produksjonen eller produksjonsmiljøet til et industriselskap. Gjennom denne dataen kan industriselskapet lære mer om egen produksjon og på den måten effektivisere driften og/eller oppnå økt kvalitet for produktet som selges. I avtalen mellom teknologiselskapet og industriselskapet, vil teknologiselskapet stort sett alltid ha sikret at de immaterielle rettighetene til teknologien forblir hos teknologiselskapet. Derimot kan reguleringen av bruken av dataen som teknologien samler inn, være mindre gjennomtenkt.
Partene vil normalt ha avtalt at industriselskapet kan bruke dataen. Det er gjerne hele poenget, og industriselskapets rett til slik bruk kan derfor også være mer implisitt. Men det kan være uklart om denne bruken er eksklusiv, eller om også teknologiselskapet kan bruke dataen til sine formål. Teknologiselskapet ønsker typisk gjerne å bruke dataen som treningsgrunnlag for sin egen KI/teknologi, slik at KI-en utvikler seg til det bedre og øker sin konkurransedyktighet. Hvis KI-en f.eks. plukker opp at industriselskapet oppnår økt salg på bestemte klokkeslett eller forbedret kvalitet ved bruk av en bestemt ingrediens eller metode, er dette informasjon KI-en vil besitte når industriselskapets konkurrenter senere kjøper den samme eller neste generasjon av teknologien. Veien kan da være kort til at dataen direkte eller indirekte gjøres kjent for konkurrenten. Et annet problem ved teknologiselskapets bruk av dataene, kan være at dataene fra industriselskapet kan være underlagt konfidensialitetsforpliktelser overfor industriselskapets øvrige kontraktsmotparter, f.eks. industriselskapets kunde eller underleverandør. Teknologiselskapets bruk av dataen til kan altså i flere henseender være direkte i strid med industriselskapets interesse.
Det er viktig å ta hensyn til problemstillinger som dette når avtalen utformes. Et eksempel på en avtaleregulering som gir teknologiselskapet slik rett, kan f.eks. lyde slik:
“[Teknologiselskapet] may use Customer Data to enhance and provide services, including the use of machine learning algorithms to improve functionality and performance”
Industriselskapet bør ikke, i alle fall ikke uten videre, akseptere slike avtaleklausuler hvis det kan bli et forretnings- eller konkurransesensitivt problem at KI-en lærer dataen som samles inn. Samtidig vil det ofte være lite interessant for teknologiselskapet å inngå en avtale som helt forbyr selskapet å bruke dataen, all den tid fremtidig salg av teknologien forutsetter videreutvikling. Dette er imidlertid ikke binært: Det finnes avtaletekniske løsninger som ligger imellom at teknologiselskapet gis ubegrenset rett og ingen rett til bruk av dataen. I den grad det er mulig, bør en slik løsning tilstrebes for å ivareta begge parters interesser.
Potensiell bruk og deling av forretningshemmeligheter vil være et helt sentralt moment ved vurderingen av hvordan en slik avtale bør utformes.
I forretningshemmelighetsloven § 2 er en forretningshemmelighet definert slik:
Med forretningshemmeligheter menes opplysninger som
er hemmelige i den forstand at opplysningene ikke som helhet, eller slik de er satt sammen eller ordnet, er allment kjent eller lett tilgjengelig
har kommersiell verdi fordi de er hemmelige
innehaveren har truffet rimelige tiltak for å holde hemmelige
Dersom forretningshemmeligheter ukritisk mates inn i en KI-løsning, uten kontraktmessige reguleringer, kan opplysningene potensielt miste sin status og sitt vern som forretningshemmelighet under forretningshemmelighetsloven, med de følgekonsekvenser det får. Avtaleteknisk er det fullt mulig å ekskludere forretningshemmeligheter (og annen informasjon som vil vernes om) fra teknologiselskapets bruksrett. Dette kan for eksempel gjøres gjennom en innsnevring av definisjonen av “Customer Data” i kontraktseksemplet gitt ovenfor. Praktiseringen av dette er imidlertid trolig mer utfordrende.
Et annet kommersielt hensyn som må tas, er hvorvidt det kan forsvares at annen generell innsikt og know-how som ikke utgjør forretningshemmeligheter etter forretningshemmelighetsloven kan brukes for å videreutvikle et KI-produkt hvis dette kan komme konkurrenter til gode. Av denne årsaken ser vi at flere og flere bedrifter implementerer interne forbud og retningslinjer mot bruk av KI-verktøy.
Denne typen sikkerhetsrisiko knyttet til bruk av data for trening av KI-verktøy har vært høyaktuelle den siste tiden. Et eksempel på det siste er Apple, som 10. juni 2024 offentliggjorde at selskapet skal bruke data lagret lokalt på din iPhone blant annet til å etablere et personlig tilpasset skriveverktøy og til å forbedre «Siri»-funksjonen. Dette gjøres gjennom en nysatsing som Apple snedig nok har kalt Apple Intelligence. Ambisjonen er blant annet at «Siri» skal utvikles fra å være en lenge utdatert og lite nyttig funksjon, til et skikkelig KI-verktøy som i langt større grad forstår hva du spør og hvilke svar du er ute etter – basert på dine egne data lagret på telefonen. Siden dataen lagret lokalt på telefonen likevel ikke gir godt nok treningsgrunnlag for Siri, vil Apple i tillegg bygge inn ChatGPT (utviklet av OpenAI) i iPhone og andre Apple-produkter. Elon Musk, hvis motiver er usikre og troverdighet er omstridt, var raskt ute med å kritisere Apples annonserte løsning.

En ytterligere problemstilling som gjør seg gjeldende særlig i B2B-forhold, er reguleringen av ansvar. Bruk av KI-løsninger har flere iboende risikoelementer ved seg. Som kjent kan KI-verktøyet være unøyaktig, ta direkte feil eller gi svar og resultater som innehar utvalgsskjevheter (såkalt «bias»). Slike utvalgsskjevheter er allerede velkjente for de fleste. Oversettelsesprogrammer som Google translate har lenge vært kritisert for å inneha tilbøyeligheter for utslagsskjevheter. Et kjent og konkret eksempel finnes nedenfor:
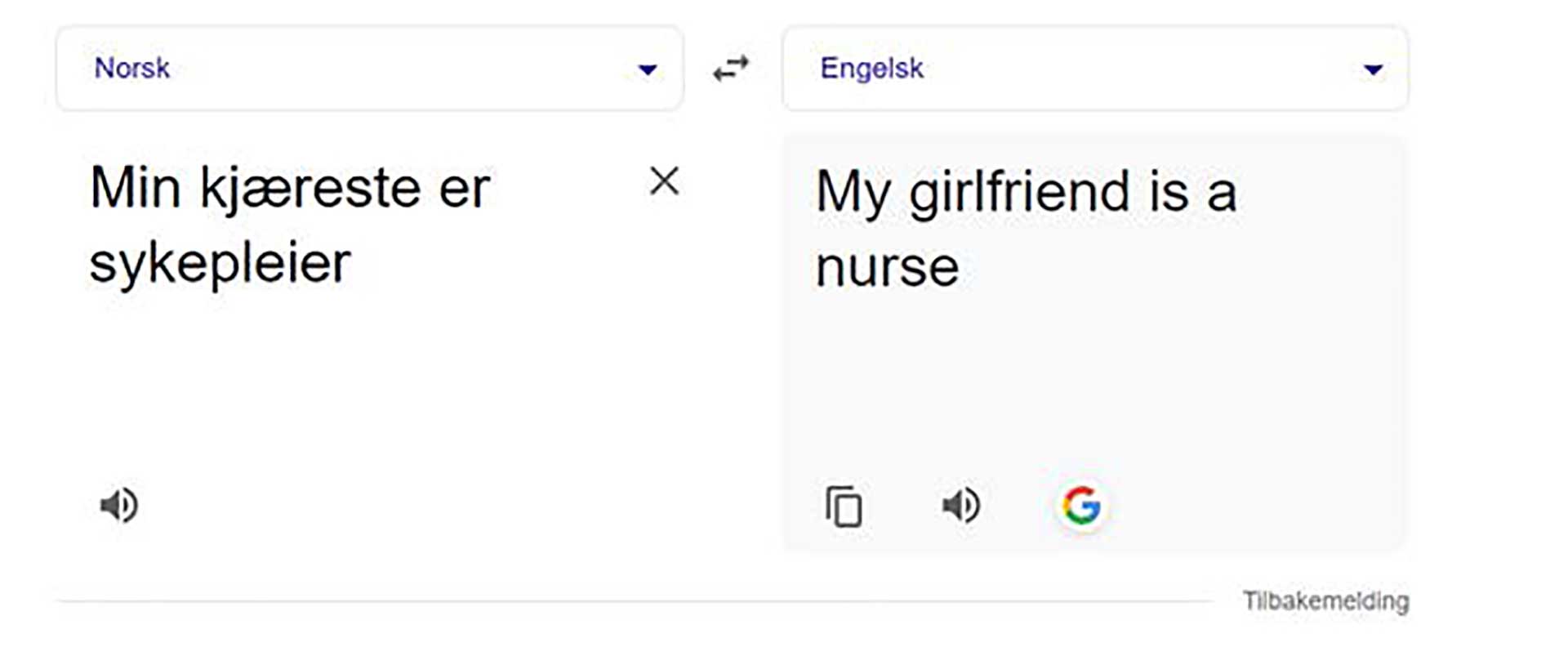
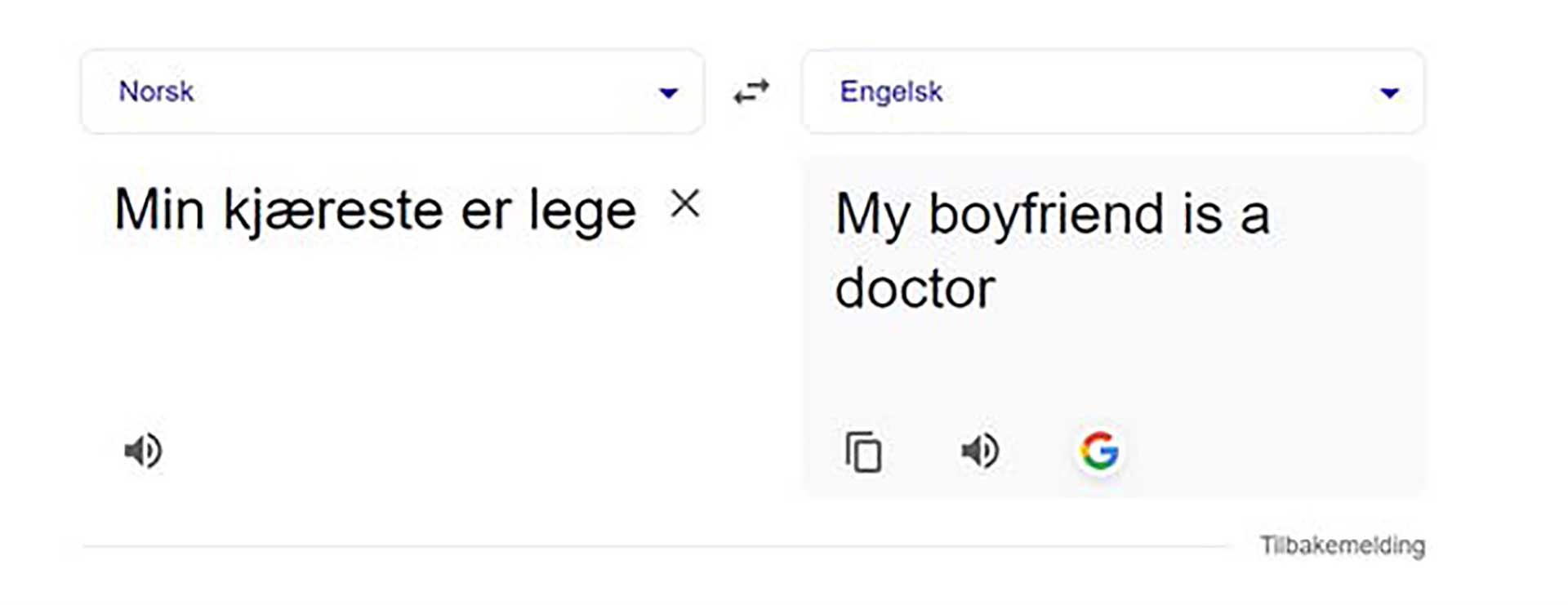
Selv om eksemplet ovenfor kan virke nokså «uskyldig», oppstår det en rekke problemstillinger knyttet til reguleringen av ansvaret i tilfeller hvor næringslivet skal ta i bruk KI-løsninger. Det kan være vanskelig å oppdage slike underliggende feil og fordommer, som likevel kan få større konsekvenser. Amazon besluttet eksempelvis for noen år siden å stanse eksprementeringen med et KI-basert rekruteringssystem fordi det ble oppdaget at rekruteringssystemet foretrakk menn foran kvinner.(3)https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G/ I et tenkt tilfelle hvor en slik løsning faktisk ble brukt, vil et selskap potensielt kunne gjøre seg skyldig i et ubevisst lovbrudd, herunder likestillings- og diskrimineringsloven. Dette vil igjen reise det kontraktrettslige spørsmålet: Hvis kunden kommer i ansvar for dette og dermed lider et økonomisk tap, kan kunde kreve dette økonomiske tapet erstattet fra KI-leverandøren?
I utgangspunktet vil det være kunden som er ansvarlig, både for eventuell foretaksstraff ilagt av myndighetene og potensielle erstatningskrav fra kandidater som mener seg forbigått. En videreføring av dette ansvaret i form av krav mot KI-leverandøren, kan komme på tale hvis nevnte “bias” utgjør et brudd på avtalen mellom selskapet og KI-leverandøren. Det kan i teorien også tenkes at kunden fremmer krav om erstatning mot KI-leverandøren på deliktsgrunnlag, samt at kandidaten fremmer direktekrav mot kunden. Slike tilfeller er imidlertid neppe særlig praktiske. Skulle det oppstå tvist om et slikt spørsmål, vil det også oppstå vanskelige bevismessige vurderinger: Ville egentlig kunden kommet til et annet resultat om KI-verktøyet ikke hadde utvalgsskjevheter, eller hvis kunden ikke brukte KI-verktøyet overhodet? Har kunden implementert tilstrekkelige tiltak på sin side for å redusere den kjente risikoen knyttet til slik «bias», osv.?
Et annet eksempel som kan trekkes frem, er hvordan den kontraktsrettslige ansvarsfordeling bør være i tilfeller hvor KI-verktøyet genererer resultater som krenker tredjeparters immaterielle rettigheter. Generative KI-løsninger er trent for å generere nye data, og vil ofte være trent på store mengder data (bilder, tekst og annet innhold) som er hentet fra internett. Treningsdataen kan derfor være beskyttet av immaterielle rettigheter. Når slike KI-løsninger brukes for å generere nytt innhold, oppstår det en risiko for at det genererte innholdet er for likt beskyttet treningsdata og at bruken av det genererte innholdet derfor kan medføre krenkelser av tredjeparters immaterielle rettigheter.
Treningsdata fra internett kan også være underlagt lisensbestemmelser, som for eksempel open source-lisenser. Flere open source-lisenser, som for eksempel GPL-lisensen, oppstiller krav om at avledede verk må distribueres under samme lisens. Slike lisensvilkår kan være problematiske i en kommersiell sammenheng, hvor selskaper typisk ønsker å bevare egen kildekode proprietær og distribuere slik kildekode under egen lisens. Vi har erfaring med selskaper som har blitt møtt med krav fra open source-lisenshavere om at bruken av slik kildekode er i strid med lisensvilkårene. I tilfeller vil det være snakk om et potensielt opphavsrettslig brudd som kan gi grunnlag for krav på økonomisk kompensasjon og opphør av bruken, hvor selve utskiftningen av kildekoden kan være både tid- og ressurskrevende.
I immaterialrettslovgivningen er ikke utvist skyld et vilkår for å fastslå en krenkelse. Dersom det genererte innholdet er likt nok, vil bruken av KI-løsningen med andre ord kunne resultere i krav om at bruken opphører og økonomisk kompensasjon. Denne risikoen er særlig stor dersom KI-modellen er trent på et begrenset datasett. Fra et kontraktsrettslig perspektiv vil utgangspunktet være at kunden er ansvarlig for egen bruk av innholdet som er generert fra KI-løsningen.
halBedrifter som ønsker å ta i bruk KI-løsninger i egen virksomhet bør derfor ha et bevisst forhold til denne risikoen når det inngås avtale med en KI-leverandør. For eksempel kan det være aktuelt å innta reguleringer som sikrer at KI-leverandøren har inngått riktige lisenser for bruk av treningsdataen, eller at KI-løsningen ikke skal trenes på spesifikt innhold som for eksempel open source-lisensiert kildekode. Det vil også være aktuelt å implementere avtalereguleringer som sikrer at kunden holdes skadesløs for potensielle brudd på tredjeparters immaterielle rettigheter.

